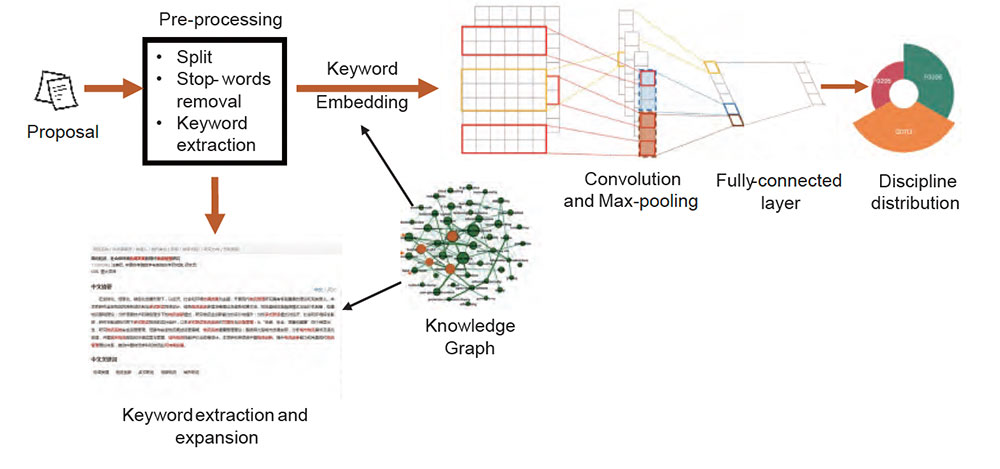
Extreme labeled scientific text classification is an important and challenging task in research management and technology transfers. Based on the practical needs in research and innovation, we have proposed an artificial intelligent (AI) approach to assist users in classifying scientific text (e.g., research projects, papers and patents) into extreme labels (e.g., 1,000 discipline area codes).
As shown in the above Figure, the proposed AI approach uses research knowledge graph, natural language processing (NLP) and deep learning methods to classify scientific text with extreme multi-labels in the following steps.
- Knowledge graph construction. A research knowledge graph is constructed based on over 70 million scientific text (i.e., funded projects and research papers with titles, abstracts and disciplines/ keywords,) the relationships between research entities (e.g., researchers, projects, papers, disciplines and keywords) are mined and extracted, including the co-occurrence relationship between keywords, the collaboration and citation networks among researchers, the affiliation with projects and publications, etc.
- Text preprocessing and keyword extraction. An English-Chinese bilingual natural language process tool is developed and used to conduct word segmentation, stop word filtering, and keyword extraction to generate the important keyword on a given scientific text.
- Keyword embedding based on research knowledge graph. The keyword co-occurrence network is used to learn the word embedding with the method of graph representation, where the trained word embedding is used to represent the keywords in the target text.
- Text classification based on convolutional neural networks. The word embedding of the target text can be inputted into the neural network. The neural network model of TextCNN is employed to extract the scientific text features. The neural network parameters is trained based on the scientific text with discipline codes.
Using over 100,000 scientific text (e.g., projects and publications) with labeled discipline code classifications, we have conducted experiments to evaluate the performance of scientific text classification in terms of three evaluation metrics, i.e., precision, recall, and F1-score. The experiment results have shown that the proposed approach is superior to the current methods of TF-IDF, KNN, SVM, LSTM, etc. The proposed method can find wide applications in research management and technology transfers.
Funded by the National Science Foundation of China (NSFC), the project team have applied the proposed AI approach to solve the peer reviewer assignment problem, where both research proposals and reviewers are classified into detailed research discipline codes (over 1,000 discipline codes in NSFC) so as to maximise the research similarities under the same discipline area.
Funded by the Shenzhen Hong Kong Innovation and Technology Fund, the project team is also applying the proposed AI approach to classify patents and companies into detailed industry sectors so as to match their expertise for technology transfers.